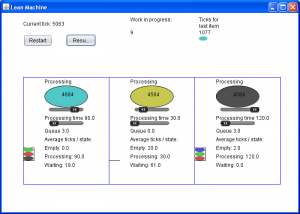
Eclipse trashed some code for me today and I had to recreate the workspace. On such days, I can get a bit edgy and maybe I was, when commenting Richard Kronfält’s blog on Scrum and traditional QA.
Sorry about that, Richard, but you are a viking so I guess I can get away with a glass of mjöd if I ever bump into you.
But my point is still, requirements specification is waste. It follows from that the issue tracking is as well. Well, not always.
Continue reading