



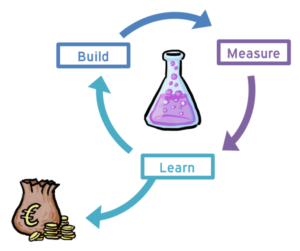
 In my team, we are working on improving real-time performance for our main service. The goal is to have response times below 100 ms in the 95th percentile and below 200 ms in the 99th percentile for certain database volumes and request frequencies.
In my team, we are working on improving real-time performance for our main service. The goal is to have response times below 100 ms in the 95th percentile and below 200 ms in the 99th percentile for certain database volumes and request frequencies.
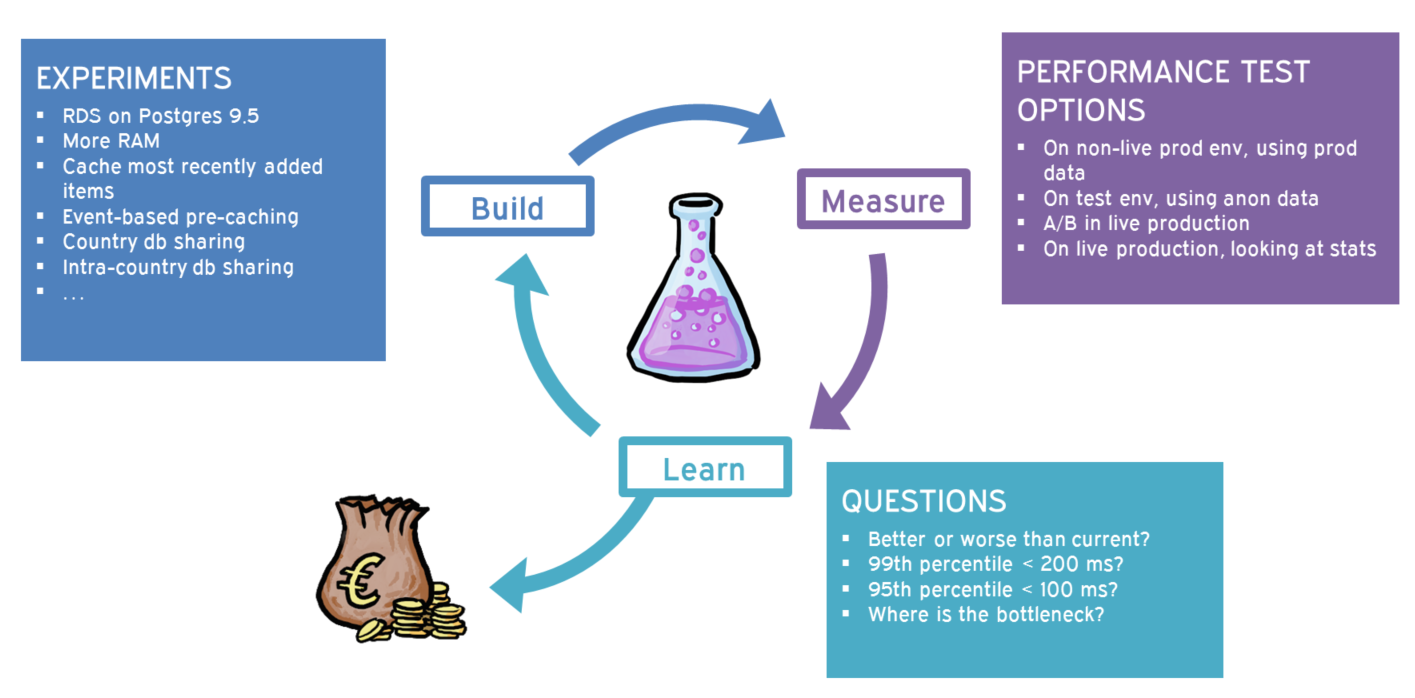
We don’t know what will be needed to reach this goal. We have some ideas, but we don’t know which one, or which ones will do the trick. We call these ideas “experiments”.
We can estimate each experiment, but we don’t know how many we will need to do to reach the goal.
This is the story of how we apply the scientific method to working with performance improvements.
We sort the experiments in the order we would like to try them. The cheap experiments are high up on the list. It’s a simple cost/benefit analysis.
When we have prepared an experiment, we run it and measure the results. We have a couple of different ways of running and measuring. One is using synthetic and anonymized test data. With this, we can generate any request volume and any database volumes. One benefit with this setup is that we can “look into the future” by simulating volumes that we do not yet have in production. It’s fairly easy to run, but was not cheap to set up in the first place.
When results have been collected, we analyse them. Are they better than before? Do we meet our goal? If it is better than before, we make the experiment production ready and incorporate it properly into our service.
If we want more confidence in the outcome of the experiment before taking it fully live, we put it live for a fraction of our production requests in a A/B test. If it still looks good, we roll it out for all live requests. This way of running and measuring was actually easier to set up, but getting the experiment into a production ready state adds some work not needed for the synthetic test. With our live A/B test setup, we can not test with higher load than we have in production. A benefit of live A/B testing is that it is live, so we test the production implementation of the experiment, with real production data, with real request behaviour and distribution. As good as our synthetic test data is, nothing beats testing in production.
If the results are so good that we meet our goal, we can choose to stop improving performance and work on something else. If not, we try the next experiment in the list.
At first, when we told our Product Owner that we had no idea how much time we would need to reach our performance goal, she looked quite nervous and hesitant. When we explained the idea of trying this way of working, with a list of experiments, a couple of different ways of running and measuring and a couple of simple questions (and non-simple answers) to determine if we need to experiment more, then she became very enthusiastic and engaged in the process.
I will update this post with links to potential follow up posts!