
You can get a fair feeling for any software system’s quality by putting in just two hours. Here’s how.
Continue reading
7 Rules on Code Readability
What makes good code? Many things but whatever the qualities are, readability is a cornerstone. If you can’t read the code, you can’t fix it. So how do you write readable code? I’ll give you my view but it’s like books, what I find enjoyable may be different from you.
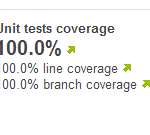
Bragging: 100% coverage, specification by example and pair programming
Yesterday we ended our second two-week sprint and on the demo, besides showing the system, we could do some bragging about test coverage using our Sonar dashboard. We also could show Fitnesse tests at system level that implements the specification by example technique, or like some say, executable requirements.

The Solution to Technical Debt
(related article: Good and Bad Technical Debt – and how TDD helps)
(Translations: Russian)
Are you in a software development team, trying to be agile? Next time the team gets together, ask:
How do we feel about the quality of our code?
Everyone rates it on a scale of 1-5, where 5 means “It’s great, I’m proud of it!” and 1 means “Total crap”. Compare. If you see mostly 4s and 5s, and nothing under 3, then never mind the rest of this article.
If you see great variation, like some 5s and some 1s, then you need to explore this. Are the different ratings for different parts of the code? If so, why is the quality so different? Are the different ratings for the same code? If so, what do the different individuals actually mean by quality?
Most likely, however, you will see a bunch of 2s or worse, and very few 4s and 5s. The term for this is Technical Debt, although for the purpose of this article I’ll simply call it Crappy Code.
Congratulations, you have just revealed a serious problem! You have even quantified it. And it took you only a minute. Anyone can do this, you don’t have to be Agile Coach or Scrum Master. Go ahead, make it crystal clear – graph the results on a whiteboard, put it up on the wall. Visualizing a problem is a big step towards solving it!
Don’t worry, you aren’t alone, this is a very common problem. <rant>However, it’s also a very stupid, unnecessary problem so I’m baffled by why it is so common.</rant>
Now you need to ask yourselves some tough questions.
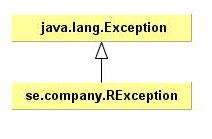
Code archeology 101: Custom Exception Hierarchies
After having worked with various legacy codebases one discovers certain recurring traits and patterns. The topic of today is the Custom Exception Hierarchy encountered in Java legacy code. This phenomenon is rather Java-specific because of that language’s checked exceptions.
So what is a Custom Exception Hierarchy? It’s an exception hierarchy, with some strangely named exception at its root, present throughout the entire codebase and used everywhere. The author(s) of such hierarchy obviously felt that exceptions like IllegalStateException or IllegalArgumentException, or the like weren’t sufficient for the sophisticated needs of their application, so they came up with a better suited hierarchy of checked exceptions.

Write Legacy Code and Secure Your Job
In this day and age with unstable economics, constant change in how to work with software, new languages and databases popping up from nowhere, it is important to cement yourself into your position at work.
Follow this guide and be sure of never being fired, no matter what.Continue reading
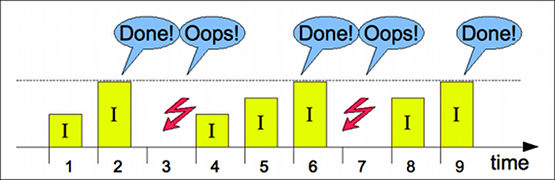
TDD Illustrated
I am planning an introductory course on TDD. In that process I have been thinking about how to convey the productivity gain with TDD.
Being a visual person, I had an idea that would illustrate this in a few pictures. Here they are for your scrutiny and enjoyment!
Continue reading
Understanding a System
I teach a course on System Architecture. It is a three-day course attended by experienced developers who want to go further in some respect.
What strikes me most is that the majority has never read any architecture document. Since writing such documents is one of the main topics of the course, I have a long road for them as they haven’t read any.
So, when you are faced with a system that you are about to change, how do you go about to understand it?
Continue reading