



 How should you structure your Ansible variables in playbooks calling cloud modules? Ansible has extensive support for variables at different levels (there are 21 different levels!).
How should you structure your Ansible variables in playbooks calling cloud modules? Ansible has extensive support for variables at different levels (there are 21 different levels!).
The inventory group_vars and host_vars offer enough flexibility for many use cases. However, when you are setting up cloud infrastructure, you don’t really have any hosts yet. Maybe you are setting up load balancers, instances, security groups and such things. Perhaps you want to setup the same things in several different environments (like “staging” and “production”). You want to re-use the same playbook, but adapt what it does by using different variable values in different environments.
In this post, I will demonstrate a way to structure Ansible variables in a playbook which pretends to setup a AWS AutoScalingGroup. I will show how you can separate the configuration for different environments by using a inventory directory. As a bonus, I will give you a neat trick to automatically load a extra variable file for each environment. We will use this to load a separate secrets file which is encrypted with git-crypt.
git-crypt is a easy way to keep passwords and other secrets in the repository, but keep them secret for people who have access to the repository, if they don’t also have a key to decrypt the repository. Read more about git-crypt on GitHub.
All of the code for this post can be found at: https://github.com/betrcode/ansible-infrastructure-variable-structure
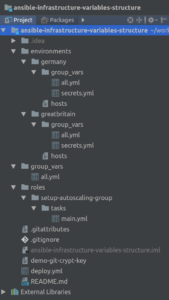
Overview of structure
The playbook is called deploy.yml. It’s very simple and looks like this:
---
- hosts: localhost
connection: local
gather_facts: no
roles:
- role: setup-autoscaling-group
As you can see, there is no explicit loading of any variables. Instead, this is managed by the group_vars in each inventory directory. We have two of those inside the “environments” directory, one for each environment. For this demo, we pretend that we have a “germany” environment and a “greatbritain” environment.
In each of the inventory group_vars directories, we have two files: all.yml and secrets.yml We will cover the secrets.yml in a bit. The all.yml is loaded automatically since all hosts (including localhost) is part of a virtual group “all”. This is where you can put all variables that are changed per environment. If you have a variable which is specific per environment, put it in environments/ENVIRONMENT_NAME/group_vars/all.yml and it will be loaded automatically when you call your playbook like this:
ansible-playbook -i environments/ENVIRONMENT_NAME deploy.yml
If you have variables that are the same in all environments, you could hardcode them into the role. But I wouldn’t recommend that. Your Ansible role should be as portable as possible. It should not contain any variables specific to your setup. It can contain good default values, if such exist. All sensitive variables should be passed into the role and stored outside of the role.
So, you probably want to have it outside the role, in a playbook variable. Then you can put the variable in the REPO_ROOT/group_vars/all.yml
--- # This file will be loaded automatically, since every host (even localhost) is part of the "all" group. top_all: name: "Sweet Vars" description: "These vars will be loaded by all - regardless of environment."
We now have a way to:
1) Have different variable values per environment
2) Have a set of variables that are the same for all environments
And they are all loaded implicitly. Simple!
What about the secrets?
As mentioned before, I also wanted to share a neat trick of how to automatically load your secret variables.
Since we have no hosts therefore can’t really have different host groups, we have different inventory folders for each environment. In there we have group_vars/all.yml for all the variables for each environment. But we want that file in clear text and a separate file for our encrypted secrets. So how do we get two separate files loaded for each environment?
The solution is to create a hostgroup and put our only host (localhost) into that group. Let’s call the group “secrets”.
[secrets] localhost
This hosts file needs to be put into each environment folder. It simply means that “localhost” is now part of the group “secrets”. So, when we run the play with “hosts: localhost”, Ansible will see that localhost is part of the secrets group and load group_vars/secrets.yml. The name of the group and the filename must match but “.yml” is optional.
This way, we can add any number of environments, and easily get both environment specific variables and environment specific secrets loaded.
Why keep secrets.yml in a separate file? Why not just encrypt everything? Well, you could do that, but it is not a good idea. First of all, you won’t be able to see differences in clear text in your version control tool (GitHub/Bitbucket etc). Second, you won’t be able to share any of the code to anyone except the ones that have the encryption key.
Demo run!
Let’s try to run the playbook and check the output!
First, you need to decrypt the secrets:
git-crypt unlock demo-git-crypt-key
Then, you can run the playbook:
ansible-playbook -i environments/greatbritain deploy.yml
Output:
PLAY [localhost] **********************************************************************************************************************
TASK [setup-autoscaling-group : Show loaded variables, just to see what got loaded] ***************************************************
ok: [localhost] => (item=top_all) => {
"item": "top_all",
"top_all": {
"description": "These vars will be loaded by all - regardless of environment.",
"name": "Sweet Vars"
}
}
ok: [localhost] => (item=environment_all) => {
"environment_all": {
"name": "Great Britain",
"region": "eu-west-1"
},
"item": "environment_all"
}
ok: [localhost] => (item=environment_secrets) => {
"environment_secrets": {
"password": "pN/f!F:$e>59!Efv",
"username": "bill.watterson"
},
"item": "environment_secrets"
}
TASK [setup-autoscaling-group : Pretend to setup autoscaling group] *******************************************************************
ok: [localhost] => {
"msg": "Setting up autoscaling group in region: eu-west-1 for environment: Great Britain"
}
PLAY RECAP ****************************************************************************************************************************
localhost : ok=2 changed=0 unreachable=0 failed=0
And now let’s try to run it with another environment!
ansible-playbook -i environments/germany deploy.yml
Output:
PLAY [localhost] **********************************************************************************************************************
TASK [setup-autoscaling-group : Show loaded variables, just to see what got loaded] ***************************************************
ok: [localhost] => (item=top_all) => {
"item": "top_all",
"top_all": {
"description": "These vars will be loaded by all - regardless of environment.",
"name": "Sweet Vars"
}
}
ok: [localhost] => (item=environment_all) => {
"environment_all": {
"name": "Germany",
"region": "eu-central-1"
},
"item": "environment_all"
}
ok: [localhost] => (item=environment_secrets) => {
"environment_secrets": {
"password": "5nj8[mcQqPTzSgq{",
"username": "douglas.adams"
},
"item": "environment_secrets"
}
TASK [setup-autoscaling-group : Pretend to setup autoscaling group] *******************************************************************
ok: [localhost] => {
"msg": "Setting up autoscaling group in region: eu-central-1 for environment: Germany"
}
PLAY RECAP ****************************************************************************************************************************
localhost : ok=2 changed=0 unreachable=0 failed=0
As you can see, we are debug printing all the variables, just to verify that it works as intended. The playbook does not actually create a AWS AutoScalingGroup. I might share a demo on how to do that in another post!
Further reading
If you want to read more HOWTOs about Ansible, see my other posts: https://blog.crisp.se/2016/10/20/maxwenzin/how-to-append-to-lists-in-ansible
and https://blog.crisp.se/2018/01/27/maxwenzin/how-to-run-ansible-tasks-in-parallel
Also see Ansible documentation: Variable Precedence: Where Should I Put A Variable?
And git-crypt on GitHub.
All of the code for this post can be found at: https://github.com/betrcode/ansible-infrastructure-variable-structure
Rather than using git-crypt here, you should check out Ansible Vault. This is a native Ansible tool that allows you to hand off the decryption of secrets to Ansible at run time.
http://docs.ansible.com/ansible/2.5/user_guide/vault.html
Thanks Nath! I’ve recently started using Ansible Vault for a new service. Will be interesting to compare Ansible Vault vs git-crypt, especially when used in a repository where you might have other non Ansible related secrets too.